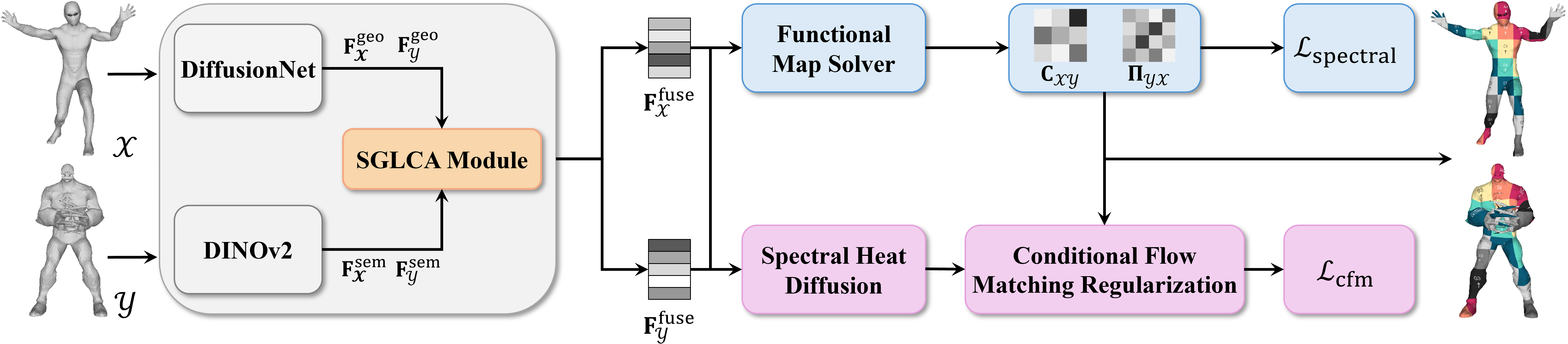
(Left): Colormap transfer on the SHREC'19 dataset demonstrates that incorporating semantic features resolves ambiguity and yields globally consistent correspondences. (Right): Vertex transfer on the SMAL dataset shows that the proposed conditional flow matching regularization promotes spatially smooth correspondences.